This note is based on Natural Language Processing with Python - Analyzing Text with the Natural Language Toolkit. I’ve uploaded the exercises solution to GitHub.
Texts and words
Texts are represented in Python using lists. We can use indexing, slicing, and the len() function.
Some word comparison operators: s.startswith(t), s.endswith(t), t in s, s.islower(), s.isupper(), s.isalpha(), s.isalnum(), s.isdigit(), s.istitle().
Searching
text1.concordance("monstrous")
A concordance view shows us every occurrence of a given word, together with some context.
A concordance permits us to see words in context.
text1.similar("monstrous")
We can find out other words appear in a similar range of contexts, by appending the term similar to the name of the text, then inserting the relevant word in parentheses. (a bit like synonyms)
text2.common_contexts(["monstrous", "very"])
The term common_contexts allows us to examine just the contexts that are shared by two or more words.
text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])
We can determine the location of a word in the text: how many words from the beginning it appears. This positional information can be displayed using a dispersion plot.
Fine-grained Selection of Words
The mathematical set notation and corresponding Python expression.
[w for w in V if p(w)]
1 | V = set(text1) |
Collocations and Bigrams
The bigram is written as ('than', 'said') in Python.
A collocation is a sequence of words that occur together unusually often. Collocations are essentially just frequent bigrams, except that we want to pay more attention to the cases that involve rare words. In particular, we want to find bigrams that occur more often then we would expect based on the frequency of the individual words.
1 | list(bigrams(['more', 'is', 'said', 'than', 'done'])) |
A frequency distribution tells us the frequency of each vocabulary item in the text.
FreqDist can be treated as dictionary in Python, where the word(or word length, etc) is the key, and the occurrence is the corresponding value.
1 | fdist1 = FreqDist(text1) # invoke FreqDist(), pass the name of the text as an argument |
functions defined for NLTK’s Frequency Distributions can be found here
Text Corpora and Lexical Resources
Accessing Text Corpora
A text corpus is a large, structured collection of texts. Some text corpora are categorized, e.g., by genre or topic; sometimes the categories of a corpus overlap each other.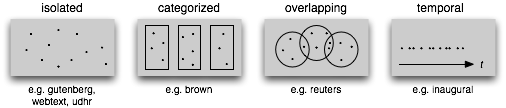
The NLTK has many corpus in the package nltk.corpus. To perform the functions introduced before, we have to employ the following pair of statements:
1 | emma = nltk.Text(nltk.corpus.guterberg.words('austen-emma.txt')) # type cast, from StreamBackedCorpusView to Text |
A short program to display information about each text, by looping over all the values of fileid corresponding to the gutenberg file identifiers and then computing statistics for each text.
1 | for fileid in gutenberg.fileids(): |
Brown Corpus
The Brown Corpus was the first million-word electronic corpus of English, created in 1961 at Brown University. This corpus contains text from 500 sources, and the sources have been categorized by genre.(see here for detail)
We can access the corpus as a list of words, or a list of sentences. We can optionally specify particular categories or files to read.
1 | brown.categories() |
Use Brown Corpus to study stylistics: systematic differences between genres.
1 | news_text = brown.words(categories='news') |
A conditional frequency distribution is a collection of frequency distributions, each one for a different “condition”. The condition will often be the category of the text.
A frequency distribution counts observable events, such as the appearance of words in a text. A conditional frequency distribution needs to pair each event with a condition.
NLTK’s Conditional Frequency Distributions: commonly-used methods and idioms for defining, accessing, and visualizing a conditional frequency distribution of counters.
| Example | Description |
|---|---|
| cfdist = ConditionalFreqDist(pairs) | create a conditional frequency distribution from a list of pairs |
| cfdist.conditions() | the conditions |
| cfdist[condition] | the frequency distribution for this condition |
| cfdist[condition][sample] | frequency for the given sample for this condition |
| cfdist.tabulate() | tabulate the conditional frequency distribution |
| cfdist.tabulate(samples, conditions) | tabulation limited to the specified samples and conditions |
| cfdist.plot() | graphical plot of the conditional frequency distribution |
| cfdist.plot(samples, conditions) | graphical plot limited to the specified samples and conditions |
| cfdist1 < cfdist2 | test if samples in cfdist1 occur less frequently than in cfdist2 |
Reuters Corpus
The Reuters Corpus contains 10788 news documents totaling 1.3 million words. The documents have been classified into 90 topics and grouped into training and test sets.
Unlike the Brown Corpus, categories in the Reuters corpus overlap with each other, simply because a news story often covers multiple topics. We can ask for the topics covered by one or more documents, or for the documents included in one or more categories.
1 | reuters.categories('training/9865') |
Here lists some of the Corpora and Corpus Samples Distributed with NLTK. For more information consult NLTK HOWTOs.
Basic Corpus Functionality defined in NLTK:
| Example | Description |
|---|---|
| fileids() | the files of the corpus |
| fileids([categories]) | the files of the corpus corresponding to these categories |
| categories() | the categories of the corpus |
| categories([fileids]) | the categories of the corpus corresponding to these files |
| raw() | the raw content of the corpus |
| raw(fileids=[f1,f2,f3]) | the raw content of the specified files |
| raw(categories=[c1,c2]) | the raw content of the specified categories |
| words() | the words of the whole corpus |
| words(fileids=[f1,f2,f3]) | the words of the specified fileids |
| words(categories=[c1,c2]) | the words of the specified categories |
| sents() | the sentences of the whole corpus |
| sents(fileids=[f1,f2,f3]) | the sentences of the specified fileids |
| sents(categories=[c1,c2]) | the sentences of the specified categories |
| abspath(fileid) | the location of the given file on disk |
| encoding(fileid) | the encoding of the file (if known) |
| open(fileid) | open a stream for reading the given corpus file |
| root | if the path to the root of locally installed corpus |
| readme() | the contents of the README file of the corpus |
Lexical Resources
A lexicon, or lexical resource, is a collection of words and/or phrases along with associated such as part of speech and sense definition. Lexical resources are secondary to texts, and are usually created and enriched with the help of texts. For example, vocab = sorted(set(my_text)) and word_freq = FreqDist(my_text) are both simple lexical resources.
Lexicon Terminology: lexical entries for two lemmas having the same spelling (homonyms), providing part of speech and gloss information.
Wordlist Corpora
1 | # find unusual or mis-spelt words in a text corpus |
1 | # word list for solving word puzzles |
1 | # find names which appear in both male.txt and female.txt |
1 | # comparative wordlist - Swadesh wordlists |
The CMU Pronouncing Dictionary, Toolbox are introduced in the book, I’ll just omit them in the note.
WordNet
WordNet is a semantically-oriented dictionary of English, similar to a traditional thesaurus but with a richer structure. NLTK includes the English WordNet, with 155287 words and 117659 synonym sets.
Synsets
With the WordNet, we can find the word’s synonyms in synsets - “synonym set”, definitions and examples as well.
1 | # synsets |
Hyponyms and hypernyms
WordNet synsets correspond to abstract concepts, and they don’t always have corresponding words in English. These concepts are linked together in a hierarchy. (See hyponyms and in lexical relations.)
The corresponding methods are hyponyms() and hypernyms().
1 | # hyponyms and hypernyms |
Some other lexical relations
Another important way to navigate the WordNet network is from items to their components (meronyms), or to the things they are contained in (holonyms). There are three kinds of holonym-meronym relation: member_meronyms(), part_meronyms(), substance_meronyms(), member_holonyms(), part_holonyms(), substance_holonyms().
There are also relationships between verbs. For example, the act of walking involves the act of stepping, so walking entails stepping. Some verbs have multiple entailments.(NLTK also includes VerbNet, a hierarhical verb lexicon linked to WordNet. It can be accessed with nltk.corpus.verbnet)
1 | # meronyms and holonyms |
Semantic Similarity
Given a particular synset, we can traverse the WordNet network to find synsets with related meanings. Knowing which words are semantically related is useful for indexing a collection of texts, so that a search for a general term will match documents containing specific terms.
We can qualify the concept of generality(specific or general) by looking up the depth of the synset.path_similarity assigns a score in the range 0–1 based on the shortest path that connects the concepts in the hypernym hierarchy (-1 is returned in those cases where a path cannot be found). Comparing a synset with itself will return 1.
1 | right_whale = wn.synset('right_whale.n.01') |
Processing Raw Text
Accessing Text
From Web
1 | # from electronic books |
From local files
1 | f = open('document.txt') |
ASCII text and HTML text are human readable formats. Text often comes in binary formats — like PDF and MSWord — that can only be opened using specialized software. Third-party libraries such as pypdf and pywin32 provide access to these formats. Extracting text from multi-column documents is particularly challenging. For once-off conversion of a few documents, it is simpler to open the document with a suitable application, then save it as text to your local drive, and access it as described below. If the document is already on the web, you can enter its URL in Google’s search box. The search result often includes a link to an HTML version of the document, which you can save as text.

Regular Expression
I’ve uploaded my summary of regular expression in the post Regular Expression.
1 | import re |
NLTK provides a regular expression tokenizer: nltk.regexp_tokenize().
Structured Program
The basic part is discussed in my Python learning note. And in this section, I just record some unfamiliar knowledge.
Assignment always copies the value of an expression, but a value is not always what you might expect it to be. In particular, the “value” of a structured object such as a list is actually just a reference to the object.
Python provides two ways to check that a pair of items are the same. The is operator tests for object identity.
A list is typically a sequence of objects all having the same type, of arbitrary length. We often use lists to hold sequences of words. In contrast, a tuple is typically a collection of objects of different types, of fixed length. We often use a tuple to hold a record, a collection of different fields relating to some entity.
Generator Expression:
1 | max([w.lower() for w in word_tokenize(text)]) [1] |
The second line uses a generator expression. This is more than a notational convenience: in many language processing situations, generator expressions will be more efficient. In 1, storage for the list object must be allocated before the value of max() is computed. If the text is very large, this could be slow. In 2, the data is streamed to the calling function. Since the calling function simply has to find the maximum value - the word which comes latest in lexicographic sort order - it can process the stream of data without having to store anything more than the maximum value seen so far.
1 | def search1(substring, words): |
Function
It is not necessary to have any parameters.
A function usually communicates its results back to the calling program via the return statement.
A Python function is not required to have a return statement. Some functions do their work as a side effect, printing a result, modifying a file, or updating the contents of a parameter to the function (such functions are called “procedures” in some other programming languages).
1 | def my_sort1(mylist): # good: modifies its argument, no return value |
When you refer to an existing name from within the body of a function, the Python interpreter first tries to resolve the name with respect to the names that are local to the function. If nothing is found, the interpreter checks if it is a global name within the module. Finally, if that does not succeed, the interpreter checks if the name is a Python built-in. This is the so-called LGB rule of name resolution: local, then global, then built-in.
Python also lets us pass a function as an argument to another function. Now we can abstract out the operation, and apply a different operation on the same data.
1 | sent = ['Take', 'care', 'of', 'the', 'sense', ',', 'and', 'the', |
Python’s default arguments are evaluated once when the function is defined, not each time the function is called (like it is in say, Ruby). This means that if you use a mutable default argument and mutate it, you will and have mutated that object for all future calls to the function as well.
Space-Time Tradeoffs
We can test the effeciency using the timeit module. The Timer class has two parameters, a statement which is executed multiple times, and setup code that is executed once at the beginning.
1 | from timeit import Timer |
Dynamic Programming
Dynamic programming is a general technique for designing algorithms which is widely used in natural language processing. Dynamic programming is used when a problem contains overlapping sub-problems. Instead of computing solutions to these sub-problems repeatedly, we simply store them in a lookup table.
1 | def virahanka1(n): |
Four Ways to Compute Sanskrit Meter: (i) recursive; (ii) bottom-up dynamic programming; (iii) top-down dynamic programming; and (iv) built-in memoization.
Categorizing and Tagging Words
Universal Part-of-Speech Tagset
| Tag | Meaning | English Examples |
| —- | —- | —- |
| ADJ | adjective | new, good |
| ADP | adposition | on, of |
| ADV | adverb | really, already |
| CONJ | conjunction | and, or |
| DET | determiner, article | the, some |
| NOUN | noun | year, home |
| NUM | numeral | twenty-four, fourth |
| PRT | particle | at, on |
| PRON | pronoun | he, their |
| VERB | verb | is, say |
| . | punctuation marks | .,;! |
| X | other | gr8, univeristy |
Some related functions:
1 | # nltk.pos_tag() |
Automatic Tagging
The Default Tagger
Default taggers assign their tag to every single word, even words that have never been encountered before.
1 | default_tagger = nltk.DefaultTagger('NN') |
The Regular Expression Tagger
The regular expression tagger assigns tags to tokens on the basis of matching patterns.
1 | patterns = [ |
The Lookup Tagger
Find the most frequent words and store their most likely tag. Then use this information as the model for a “lookup tagger”(an NLTK UnigramTagger).
For those words not among the most frequent words, it’s okay to assign the default tag of NN. In other words, we want to use the lookup table first, and if it is unable to assign a tag, then use the default tagger, a process known as backoff (5).
1 | fd = nltk.FreqDist(brown.words(categories='news')) |
N-Gram Tagging
Unigram Tagging
Unigram taggers are based on a simple statistical algorithm: for each token, assign the tag that is most likely for that particular token.
An n-gram tagger is a generalization of a unigram tagger whose context is the current word together with the part-of-speech tags of the n-1 preceding tokens.
1 | unigram_tagger = nltk.UnigramTagger(train_sents) |
Note:
n-gram taggers should not consider context that crosses a sentence boundary. Accordingly, NLTK taggers are designed to work with lists of sentences, where each sentence is a list of words. At the start of a sentence, t_{n-1} and preceding tags are set to None.
As n gets larger, the specificity of the contexts increases, as does the chance that the data we wish to tag contains contexts that were not present in the training data. This is known as the sparse data problem, and is quite pervasive in NLP. As a consequence, there is a trade-off between the accuracy and the coverage of our results (and this is related to the precision/recall trade-off in information retrieval).
One way to address the trade-off between accuracy and coverage is to use the more accurate algorithms when we can, but to fall back on algorithms with wider coverage when necessary.
1 | # 1. Try tagging the token with the bigram tagger. |
Classification
Classification is the task of choosing the correct class label for a given input. In basic classification tasks, each input is considered in isolation from all other inputs, and the set of labels is defined in advance.
E.g., deciding whether an email is spam or not; deciding what the topic of a news article is, from a fixed list of topic areas such as “sports,” “technology,” and “politics”; deciding whether a given occurrence of the word bank is used to refer to a river bank, a financial institution, the act of tilting to the side, or the act of depositing something in a financial institution.
1 | # The example of gender identification |
The training set is used to train the model, and the dev-test set is used to perform error analysis. The test set serves in our final evaluation of the system. Just as common machine learning does.
The following content seems to focus on some methods provided by NLTK. And to learn the principles like decision tree, which is not covered in Andrew Ng’s course, I’d like to turn to Hands-on Machine Learning with Scikit-Learn and TensorFlow rather than this book. And I’ll write a new post recording notes on that book:D
(Well, I’ll come back to continue updating this post when it’s necessary to.)